백인감자
[DB]3단계 DB시스템 구조, 관계형 데이터베이스 본문
2장. 3단계 DB 시스템 구조

Internal level : 물리적인 저장장치 입장에서 DB가 저장되는 방법. 관계형이 아니다.(테이블 형태가 아니기 때문이다)
데이터의 타입이나 index유무 등 conceptual level 에 대한 저장구조를 정의한다.
Conceptual level (logical level, community logical level) :
데이터베이스의 전체적인 논리적 구조로서 모든 응용프로그램이나 사용자들이 필요로하는 데이터를 종합한 조직 전체의 데이터베이스로 하나만 존재
다른 두 level 사이에 위치 해 있다, 완벽한 관계형이다.(테이블 구조), data독립성을 가진다
physical data 독립성 : index, MyISAM 등이 바껴도 영향 안받는다.
logical data 독립성 : 테이블 이름 등이 변경 되어도 영향 안받는다.
External level (user logical level) : 사용자에게 보여지는 데이터들이 있는 곳 , 사용자들과 가장 가까운 위치다.
application programmer(C,C++,Java), end user(SQL 같은 query language), DBA 등의 사용자가 있다.
conceptional level 의 base table 의 subset 이다.
DSL 을 포함해야한다.
DSL(data sublanguage) : DDL 과 DML 의 조합이다. SQL 프로그램이라고 생각하면 된다.
DDL(data definition language) : create, drop 등의 명령어
DML(data manipulation language) : insert, delete,update,select 등의 명령어
Fig. 2.2 가 위의 설명에 대한 간단한 예시이다.

metadata : 데이터에 대한 데이터. 다른 데이터를 설명해 주기 위한 데이터이다.
metadata 의 예 : index, table 이름, column 이름 등
데이터 사전(data dictionary)는 시스템 전체에서 나타나는 데이터 항목들에 대한 정보를 지정한 중앙 저장소이다. 이 정보에는 항목을 참조하는데 사용되는 식별자, 항목에 대한 엔티티의 구성요소, 항목이 저장되는 곳, 항목을 참조하는 곳 등을 포함한다.
즉, data dictionary 는 metadata 들을 담는 structure 라고 볼 수 있다.
directory 혹은 catalog 라고불린다.
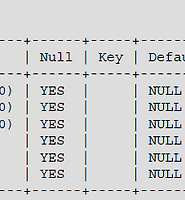
mysql에서 아래의 화면과 같이 확인해보면 information_shema 는 metadata 들을 저장한 database 라는 것을 알 수 있다.(=data dictionary)

분산형 데이터베이스 시스템(distributed database system) : 하나의 데이터베이스 관리 시스템(DBMS)이 여러 CPU에 연결된 저장장치들을 제어하는 형태의 데이터베이스이다. 물리적으로 동일한 위치에 여러 대의 컴퓨터로 구성된 경우 또는 컴퓨터 네트워크에서 상호 연결된 컴퓨터 군에 분산되어있는 경우 등이 있다. ex. 하나의 서버에 여러 client 들이 연결된 경우, 여러 대의 server-client machine 들이 communication network 를 형성하는 경우 등. transparently : 실제로는 떨어져있는데 local 처럼 사용 가능한 것 이러한 특징을 가진다.
point of view as if the data were all managed by a single DBMS running on a single machine
3장. Relation model
기존의 존재하는 tables에서 새로운 tables 를 만드는 연산은 3종류가 있다.
- SELECT(==RESTRICT) : table 에서 특정 rows(records) 를 추출해내는 것
- PROJECT : 한 table 에서 특정 columns(fields) 를 추출해내는 것
- JOIN : 두 table 에서 공통된 column 에 같은 value 가 있으면 그 record 들을 합쳐서 추출해내는 것
실습을 통해 확인해보면 우선 Fig. 3.1 과 같은 tables 를 만든다.



dept, emp 라는 두 table 에서 새로운 table 을 만들어보는 과정의 예시로 Fig. 3.2 를 보자.

위의 그림과 같은 결과가 나오기 위한 명령어들은 아래와 같다.
RESTRICT : select * from DEPT where BUDGET > ‘8M’;
PROJECT : select DEPTNUM, BUDGET from DEPT;
JOIN : select EMP.DEPTNUM, DNAME, BUDGET, EMPNUM, ENAME, SALLARY from DEPT, EMP where DEPT.DEPTNUM =EMP.DEPTNUM;
(DEPTNUM 이 두 table 에 공통으로 존재하는 field 이기 때문에 둘 중 하나의 테이블 이름을 명시해줘야 ambiguous 를 피할 수 있다.)
JOIN 을 통해서 DEPTNUM 이 일치하는 row(record) 들을 하나의 row 로 합쳐준다(join한다) 는 것을 확인 할 수 있다.
우리가 어떤 조건을 통해 table 을 만들 때 조건에 따라 위의 3가지 연산의 순서만 다르게 해도 처리과정이 훨씬 덜 복잡해진다는 것을 명심해야한다.
subquery : 서브쿼리란 하나의 SQL 문 에 포함된 다른 SQL 문을 의미한다.
EMP table 에 존재하는 DEPTNUM 과 일치하는 DEPT table 의 records 들의 DEPTNUM, BUDGET field 들만 출력해주는 것.
예시) select DEPTNUM, BUDGET from DEPT where DEPTNUM in (select DEPTNUM from EMP);

관계형 데이터베이스 시스템에서 table 은 물리적 구조가 아닌 논리적 구조이다. 즉, table 은 ADT 다 .
|
dept# |
Emp# |
|
D1 |
E1, E2 |
|
. . . |
. . . |
do not allow repeating groups
모든 relation 은 head (field) 와 body(record) 로 구성된다. --> table 을 의미한다.
'데이터베이스' 카테고리의 다른 글
| [DB/자료구조] B-Tree(B트리), B+ 트리 (6) | 2017.07.08 |
|---|---|
| [DB] 데이터베이스 복구, ACID (0) | 2016.12.18 |
| [DB] MySQL C/C++(visual studio 2015) 연동하기 (21) | 2016.09.30 |
| [DB] MySQL 기본 (0) | 2016.09.05 |